Filter Heuristics
a collection of dirty, naughty, obscene and otherwise bad holes
2024
*more detailed documentation in progress*
+++ update: a new bonus chapter coming soon! instructions of how to make your data dirty and not to be trained!+++
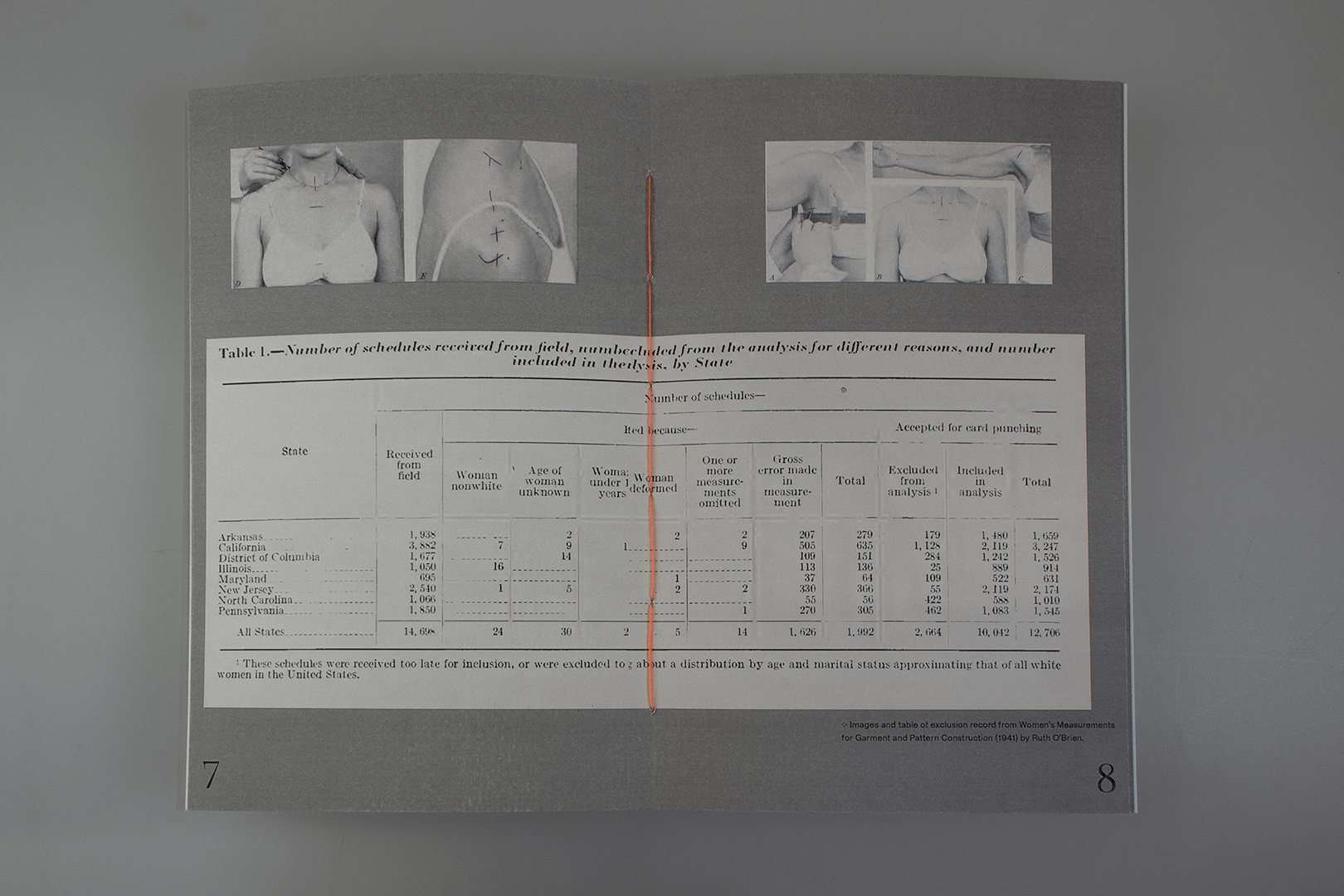
Dirty data refers to data that is somewhat faulty and requires to be removed in data preprocessing. In
1930s, non-white women’s body size data was categorized as dirty data. Now in the age of GPT, datasets
for training large models are getting too big to inspect through. With the idea of “scale averages out
noise”, scaling up by scrabbling all the data available for free on the internet then filtering out
unwanted content is the optimal choice to “move fast”. Here, what is considered as dirty data and how
are they removed from massive training materials?
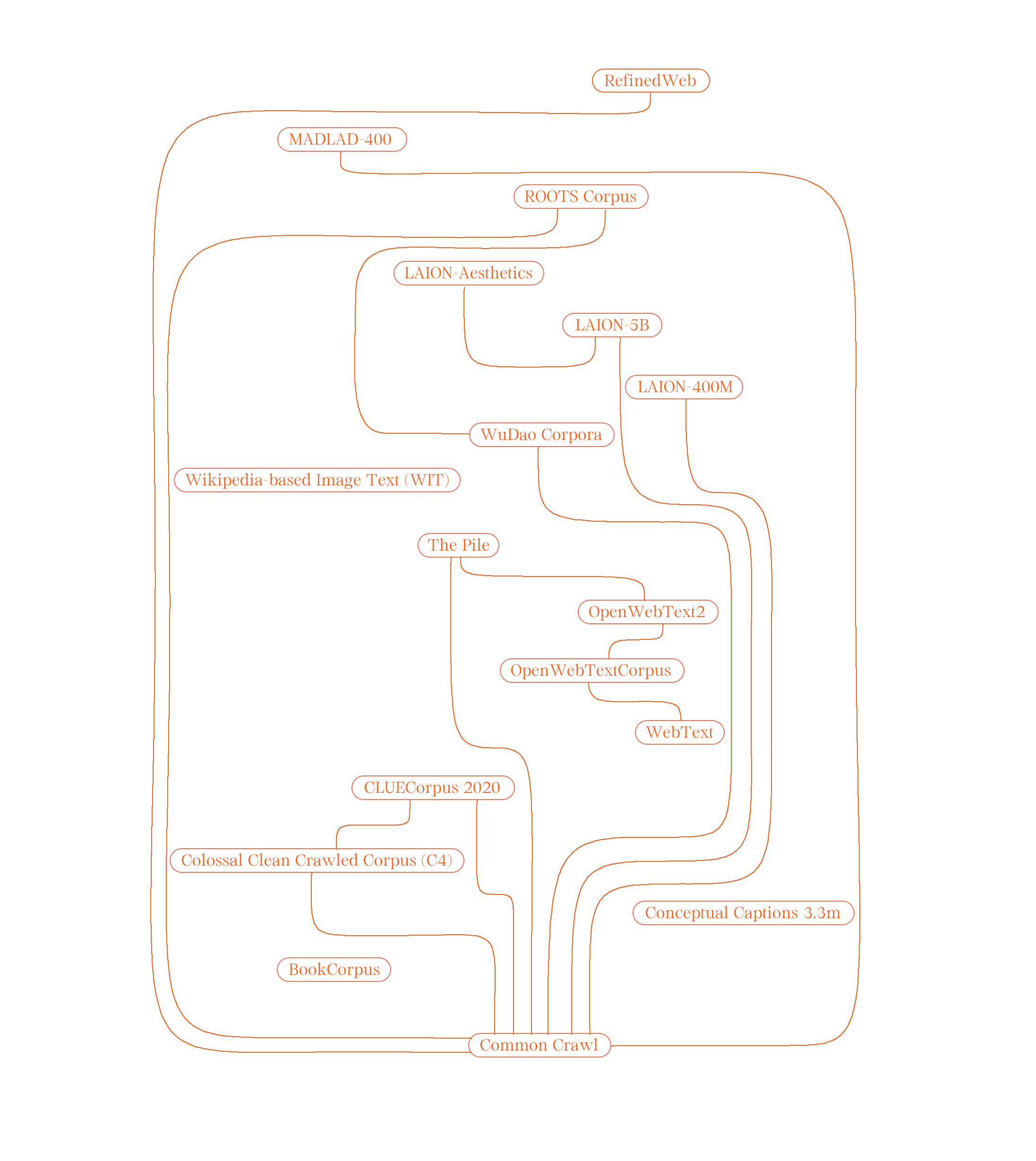
The publication looks into 17 open (or reproduced thus open) extraction-based, human-not-in-the-loop
datasets and gathers their heuristic-based methods for filtering out dirty data. A heuristic is a
practical method that, not guaranteed to be optimal, perfect, or rational, but is “good enough” solving
the problem at hand. This publication questions whether a narrative of “cleaning” in the context of
high-tech can emerge from technical papers, reflecting on these silent, anonymous yet upheld estimations
and not-guaranteed rationalities in current sociotechnical artifacts, and on for whom these estimations
are good-enough, as it will soon be part our technological infrastructures.
First edition published in April 2024.
Typefaces: Serifbabe SIGMA by Charlotte Rohde, Redaction by Jeremy Mickel, Neue Haas Grotesk.